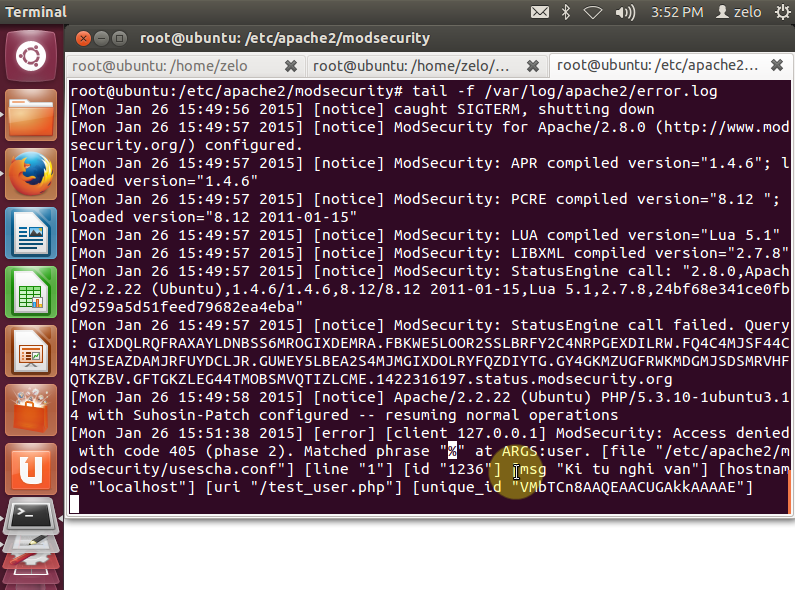
Sơ đồ tổng quan của hệ thống
Chương trình viết ra hoạt động song song với ModSecurity, bao gồm việc phân tích dữ liệu sau khi trích xuất được bằng ModSecurity và viết rule để ModSecurity áp dụng để áp dụng kiểm tra các request kế tiếp.
Chương trình phân tích dữ liệu
Đặt vấn đề và ý tưởng
Đối với chương trình phân tích dữ liệu này do dữ liệu thu được là định dạng text, chương trình sẽ tiến hành phân tích 2 đặc trưng cơ bản của dữ liệu là độ dài và kí tự phổ biến, dữ liệu được thu thập ở đây bao gồm dữ liệu bình thường và dữ liệu bất thường ( dữ liệu chứa nội dung độc hại nhằm tấn công vào hệ thống ). Dữ liệu bình thường sẽ có tần số xuất hiện cao hơn dữ liệu bất thường trong tổng số dữ liệu thu được ( Ví dụ như trong 10 đoạn dữ liệu thu thập được, sẽ có 8 đoạn dữ liệu bình thường và 2 đoạn dữ liệu không bình thường). Chương trình sẽ phân tích độ dài và kí tự của từng dòng dữ liệu (của mỗi client gửi lên) trong file dữ liệu thu thập được. Sau đó dựa vào số liệu phân tích được từ độ dài và kí tự và sau đó sẽ viết thành rule cho ModSecurity.
Hiện thực
Chương trình được viết bằng ngôn ngữ C++, gồm 3 file gen_rule.cpp, get_char.h và length.h. File get_char.h chứa hàm phân tích sự phân bố kí tự, file length.h chứa hàm phần tích phân bố độ dài dữ liệu, file gen_rule.cpp chứa hàm main để chạy 2 hàm trong 2 file trên.
Phương pháp phân tích ở đây là dựa vào tổng số dữ liệu đã có mà rút ra được độ dài thông dụng của dữ liệu, ví dụ như độ dài có tần số xuất hiện thấp sẽ xếp vào dạng dữ liệu bất bình thường. Và tương tự như vậy, đối với những kí tự thuộc tần số xuất hiện thấp sẽ được ghi lại, sau đó rule sẽ được viết ra dựa trên kết quả đã phân tích được.
Phân tích độ dài dữ liệu - length.h
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void get_length(char * file)
{
char str[10];
int index = 0;
int i = 1;
int j = 0;
FILE * f_data = fopen(file, "r");
// DEM SO DU LIEU TRONG FILE
while (!feof(f_data))
{
char c = fgetc(f_data);
if (c == '\n')
i++;
}
fseek(f_data, 0, SEEK_SET);
int *arr = new int[i];
//LUU DO DAI CUA TUNG DOAN DU LIEU VAO FILE
while (!feof(f_data))
{
char c = fgetc(f_data);
if (c == '\n')
{
arr[index] = j;
index++;
j = 0;
}
else if (c != '\n')
j++;
}
//SAP XEP LAI MANG CHUA DO DAI DU LIEU THANH MANG TANG DAN
for (int c = 0; c <= (index - 2); c++)
{
for (int d = 0; d <= index - 1 - c - 1; d++)
{
if (arr[d] > arr[d + 1])
{
int swap = arr[d];
arr[d] = arr[d + 1];
arr[d + 1] = swap;
}
}
}
// DEM SO PHAN TU KHAC NHAU TRONG MANG VUA LUU
int count_e = 1;
for (int count = 0; count < index - 2; count++)
{
if (arr[count] != arr[count + 1])
{
count_e += 1;
}
}
int per = 1, count_new = 0;
index -= 1;
int **arr_per = new int*[count_e];
//TAO MANG 2 CHIEU VA TINH TAN SO XUAT HIEN CUA TUNG PHAN TU
for (int count = 0; count < index; count++)
{
if (arr[count] == arr[count + 1])
{
per += 1;
if ((count + 1) == (index))
{
arr_per[count_new] = new int;
arr_per[count_new][0] = arr[count];
arr_per[count_new][1] = per;
}
}
else
{
arr_per[count_new] = new int;
arr_per[count_new][0] = arr[count];
arr_per[count_new][1] = per;
count_new += 1;
per = 1;
if ((count + 1) == (index))
{
per = 1;
arr_per[count_new] = new int;
arr_per[count_new][0] = arr[count + 1];
arr_per[count_new][1] = per;
}
}
}
int count_overfif = 0;
int* top, max, min;
// DEM SO LUONG PHAN TU CO TAN SO XUAT HIEN TU 15% TRO LEN
for (int count = 0; count <= count_new; count++)
{
if ((((arr_per[count][1]) * 100) / (index)) >= 15)
{
count_overfif++;
}
}
top = new int[count_overfif];
count_overfif = 0;
// LUU NHUNG PHAN TU CO TAN SO XUAT HIEN TU 15% TRO LEN
for (int count = 0; count <= count_new; count++)
{
if ((((arr_per[count][1]) * 100) / (index)) >= 15)
{
top[count_overfif] = arr_per[count][0];
count_overfif++;
}
}
for (int count = 0; count < count_overfif - 1; count++)
{
if (top[count] > top[count + 1])
{
max = top[count];
}
else{ max = top[count + 1]; }
}
for (int count = count_overfif; count > 0; count--)
{
if (top[count]<top[count - 1])
{
min = top[count];
}
else{ min = top[count - 1]; }
}
printf("Max: %d \n",max);
printf("Min: %d \n", min);
sprintf(str, "%d", max);
count_e = 0;
// DAT TEN FILE
for (int count = 0; file[count] != '.'; count++)
count_e++;
char* name = new char[5];
int length = 12;
char* name_file = new char[length];
int dem = 0;
// LAY TEN FILE TU FILE DU LIEU DE DAT TEN CHO FILE RULE
for (int count = 23; file[count] != '.'; count++)
{
name_file[dem] = file[count];
name[dem] = file[count];
dem++;
}
name[count_e] = '\0';
strcpy(name_file + length - 8, "len.conf");
FILE * test_write = fopen(name_file, "w");
char* Rule_gt_1 = "SecRule ARGS:";
char* Rule_gt_1_1= " \"@gt ";
char* Rule_gt_2 = "\" \"id:1234";
char* Rule_gt_3 = ",pass,log,msg:\'Chieu dai kha nghi\',t:length\" ";
char* Rule_lt_1 = "SecRule ARGS:";
char* Rule_lt_1_1 = " \"@lt ";
char* Rule_lt_2 = "\" \"id:1235";
char* Rule_lt_3 = ",pass,log,msg:\'Chieu dai kha nghi\',t:length\" ";
fputs(Rule_gt_1, test_write);
fputs(name, test_write);
fputs(Rule_gt_1_1,test_write);
fputs(str, test_write);
fputs(Rule_gt_2, test_write);
if(name[0] == 'u')
fputc('1',test_write);
else
fputc('2',test_write);
fputs(Rule_gt_3,test_write);
fputc('\n', test_write);
sprintf(str, "%d", min);
fputs(Rule_lt_1, test_write);
fputs(name, test_write);
fputs(Rule_lt_1_1, test_write);
fputs(str, test_write);
fputs(Rule_lt_2, test_write);
if(name[0] == 'u')
fputc('3',test_write);
else
fputc('4',test_write);
fputs(Rule_lt_3, test_write);
fclose(f_data);
fclose(test_write);
}Ở đây, khi phân tích độ dài, mỗi độ dài sẽ có tần số xuất hiện riêng, chọn những độ dài có tần số lớn hơn 15% là độ dài bình thường, còn những độ dài có tần số thấp hơn 15% xem như bất bình thường.
Phân tích phân bố kí tự - get_char.h
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void get_char(char* file)
{
FILE * f_data = fopen(file, "r");
int i = -1;
int c_e = 0;
char * arr_char;
fseek(f_data, 0, SEEK_SET);
// DEM SO LUONG KI TU TRONG FILE DU LIEU
while (!feof(f_data))
{
char c = fgetc(f_data);
if (c != '\n')
{
i++;
}
}
arr_char = new char[i - 1];
fseek(f_data, 0, SEEK_SET);
// LUU KI TU TRONG FILE DU LIEU VAO MANG
while (!feof(f_data))
{
char c = fgetc(f_data);
if (c != '\n')
{
arr_char[c_e] = c;
c_e++;
}
}
arr_char[c_e] = '\0';
// SAP XEP LAI KI TU THEO THU TU TANG DAN
for (int c = 0; c <= (c_e - 3); c++)
{
for (int d = 0; d <= c_e - 2 - c - 1; d++)
{
if (arr_char[d] > arr_char[d + 1])
{
char swap = arr_char[d];
arr_char[d] = arr_char[d + 1];
arr_char[d + 1] = swap;
}
}
}
// DEM SO PHAN TU KHAC NHAU TRONG MANG
int count_e = 1;
for (int count = 0; count < c_e - 2; count++)
{
if (arr_char[count] != arr_char[count + 1])
{
count_e += 1;
}
}
int* arr_per_num = new int[count_e];
int* arr_per_max = new int[count_e];
int per = 1, count_new = 0;
// DEM SO LAN XUAT HIEN CUA MOI KI TU
for (int count = 0; count < c_e - 2 ; count++)
{
if (arr_char[count] == arr_char[count + 1])
{
per += 1;
if ((count + 1) == (c_e - 2))
{
arr_per_num[count_new] = per;
}
}
else
{
arr_per_num[count_new] = per;
count_new += 1;
per = 1;
if ((count + 1) == (c_e - 1))
{
per = 1;
arr_per_num[count_new] = per;
}
}
}
int max = 0;
// TINH TONG SO KI TU
for (int count = 0; count < count_e; count++)
max += arr_per_num[count];
// TINH TAN SO XUAT HIEN CUA TUNG KI TU
for (int count = 0; count < count_e; count++){
arr_per_max[count] = arr_per_num[count] * 100 / max;
}
char * arr_chardif = new char[count_e - 1];
arr_chardif[0] = arr_char[0];
per = 0;
//
for (int count = 0; count < c_e - 1; count++)
{
if (arr_char[count] != arr_char[count + 1])
{
arr_chardif[per] = arr_char[count];
if ((count + 1) == (c_e - 1))
{
arr_chardif[per + 1] = arr_char[count + 1];
}
per++;
}
}
int count_char = 0;
// DEM SO KI TU CO TAN SO XUAT HIEN DUOI 1%
for (int count = 0; count < per; count++)
{
if (arr_per_max[count] <= 1)
count_char++;
}
char* arr_char_rule = new char[count_char];
count_char = 0;
// LUU NHUNG KI TU CO TAN SO XUAT HIEN DUOI 1%
for (int count = 0; count < per; count++)
{
if (arr_per_max[count] <= 1)
{
arr_char_rule[count_char] = arr_chardif[count];
count_char++;
}
}
arr_char_rule[count_char] = '\0';
count_e = 0;
// DEM SO KI TU TRONG TEN FILE DU LIEU
for (int count = 0; file[count] != '.'; count++)
count_e++;
char* name = new char[5];
int length = 12;
char* name_file = new char[length];
int dem = 0;
// LAY KI TU TRONG TEN FILE DU LIEU DE DAT TEN FILE RULE
for (int count =23; file[count] != '.'; count++)
{
name_file[dem] = file[count];
name[dem] = file[count];
dem++;
}
name[4] = '\0';
strcpy(name_file + length - 8, "cha.conf");
FILE * test_write = fopen(name_file, "w");
char* Rule_gt_1 = "SecRule ARGS";
char* Rule_gt_1_1 = " \"@pm ";
char* Rule_gt_2 = "\" \"id:1236,deny,log,msg:'Ki tu nghi van'\" ";
fputs(Rule_gt_1, test_write);
fputs(Rule_gt_1_1, test_write);
fputs(Rule_gt_2, test_write);
fclose(test_write);
fclose(f_data);
}Thuật toán phân tích tần số xuất hiện của kí tự về căn bản cũng giống với việc phân tích độ dài của dữ liệu, những kí tự thuộc tần số thấp hơn 1% sẽ được cho là kí tự nghi vấn và được liệt kê trong rule.
Đầu vào chương trình - gen_rule.cpp
#include <stdio.h>
#include "length.h"
#include "get_char.h"
int main()
{
get_length("đường dẫn tới file dữ liệu");
get_char("đường dẫn tới file dữ liệu");
printf("Da cap nhat rule moi! Dich vu Apache se duoc khoi dong lai. \n");
return 0;
}File gen_rule chứa hàm main sẽ gọi 2 hàm get_char và get_length trong 2 file length.h và get_char.h để tiến hành phân tích và tạo rule.
Biên dịch trên Ubuntu
Để chạy được file cpp trên Ubuntu, cần biên dịch trên terminal. Dùng dòng lệnh sau để biên dịch trên Ubuntu:
g++ gen_rule.cpp –o gen_rule
Sau khi thực hiện dòng lệnh này, ta chỉ cần chuyển tới thư mục chứa file .cpp ( như ở bài viết này là gen_rule.cpp) và gõ lệnh ./gen_rule để có thể chạy được chương trình.
Cài đặt chương trình chạy theo thời gian
Sau khi biên dịch chương trình thành công, tiếp theo sẽ hướng dẫn cài đặt để cho chương trình tự động chạy lại nhằm cập nhật dữ liệu mới để tạo rule mới phù hợp với dữ liệu. Bài viết này sẽ sử dụng shell scripts. Trước tiên, tạo file update_rule.sh trong cùng thư mục chứa file cpp bằng dòng lệnh:
gedit update_rule.sh
Sau đó thêm các dòng lệnh này vào:
cp /tmp/data_user.txt //đường dẫn tới data ./gen_rule cp //đường dẫn tới data/usescha.conf /etc/apache2/ModSecurity/usescha.conf cp //đường dẫn tới data/useslen.conf /etc/apache2/ModSecurity/useslen.conf service apache2 restart
Nội dung của file update_rule.sh trên theo trình tự bao gồm copy file dữ liệu đã trích xuất sang thư mục của chương trình, chạy chương trình, copy file rule đã viết sang thư mục rule của ModSecurity. Cuối cùng là khởi động lại apache2 để cập nhật rule của ModSecurity.
Tiếp theo, để gọi shell scripts thực thi theo khoảng thời gian nhất định, sử dụng cron tab:
Crontab –e
Thêm dòng lệnh này vào cuối file:
* */2 * * * * bash //Đường dẫn tới file update_rule.sh
Dòng lệnh ở trên có nghĩa là sau 2 tiếng, shell scripts sẽ được chạy lại (thực thi các dòng lệnh trong file update_rule.sh).
Sau khi chương trình thực thi, file rule sẽ được tạo ra, dưới đây là ví dụ về một file rule được tạo:
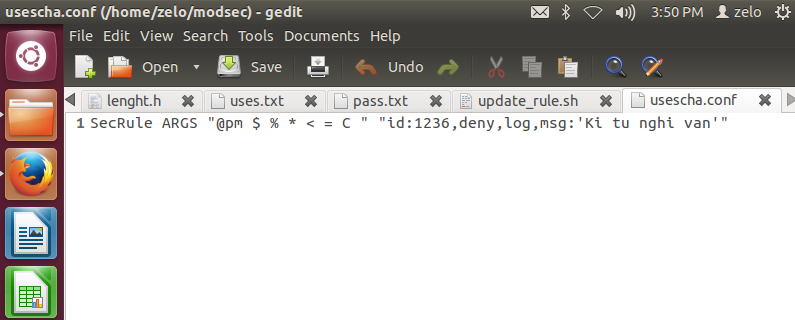
Nội dung của file rule trên là các kí tự $ % * < = C được xem như là kí tự nghi vấn, khi người dùng nhập vào dữ liệu có chứa các kí trên sẽ bị ModSecurity ghi log lại với nội dung “Kí tự nghi vấn” và sẽ bị chặn không cho gửi lên server.
Thử nghiệm
Với rule có được, thử nghiệm bằng cách nhập vào input nội dung có chứa kí tự nghi vấn được liệt kê trong rule và gửi lên server:
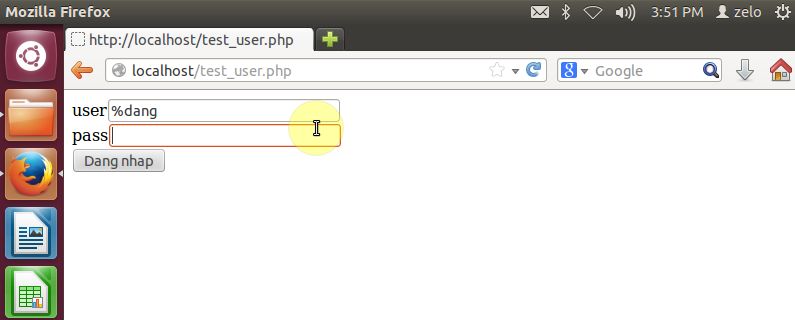
Khi gửi lên server, ModSecurity sẽ chặn và ghi log lại:
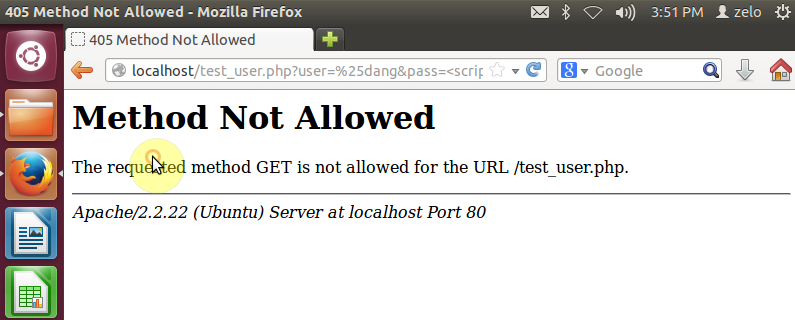
Kiểm tra log bằng dòng lệnh:
tail –f /var/log/apache2/error.log
Nội dung log do ModSecurity ghi lại theo rule đã viết: