


Vấn đề cấp phát và quản lý bộ nhớ mà hệ điều hành cung cấp đối với các kiểu dữ liệu tự định nghĩa có sự đặc biệt so với cấp phát với các kiểu dữ liệu cơ bản (char, short, int, ...). Bài viết này sẽ làm rõ tại sao hệ điều hành lại tạo ra Data Alignment.
Memory access granualarity
Khi lập trình thường thấy bộ nhớ là một chuỗi các ô nhớ liên tiếp nhau, mỗi ô nhớ tương đương với 1 byte.
Tuy nhiên, đối với hệ thống máy tính, việc đọc và ghi với từng ô nhớ như vậy tốn nhiều thời gian dẫn tới việc giảm hiệu suất. Vì vậy, tại mỗi thời điểm, processor truy cập bộ nhớ với 2-, 4-, 8-, 16- và thậm chí 32- byte tùy vào từng hệ thống. Kích thước khi một process truy cập bộ nhớ được gọi là bộ nhớ truy cập chi tiết (Memory access granularity).
Data Alignment
Xét các kết quả của các bộ nhớ truy cập chi tiết (Memory access granularity) khác nhau để có thể hiểu rõ cơ chế. Ở đây sử dụng hệ thống 32 bit - x86, nên không gian mỗi lần register load dữ liệu sẽ là 4 bytes.
Single-byte memory access granularity
Với 1 byte, register sẽ chia làm 4 phần, hiện tại các processor không sử dụng theo cơ chế này, tuy nhiên đưa ra để so sánh với cơ chế bên dưới.
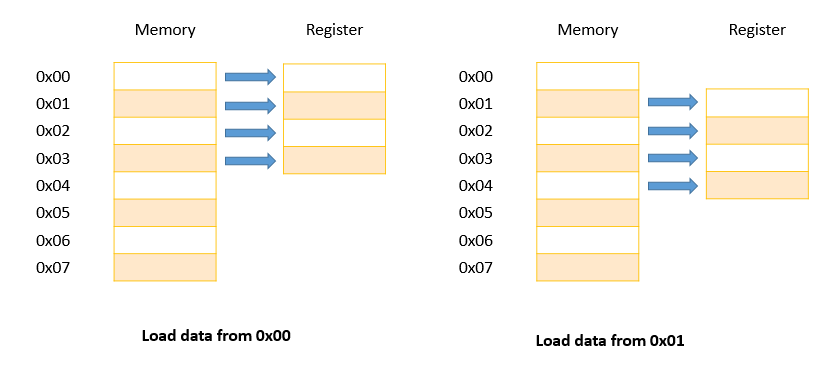
Khi đọc, ghi 4 byte từ địa chỉ 0x00 hay 0x01 đều không có sự khác biệt do truy cập ở kích thước là 1 byte.
Double-byte memory access granularity
Với 2 bytes, register được chia làm ít nhất là 2 phần. Với việc tăng gấp đôi bộ nhớ truy cập chi tiết, nghĩa là công việc giảm 1 nửa, thấy được lợi ích của mô hình này khi đọc ghi dữ liệu ở địa chỉ 0x00.
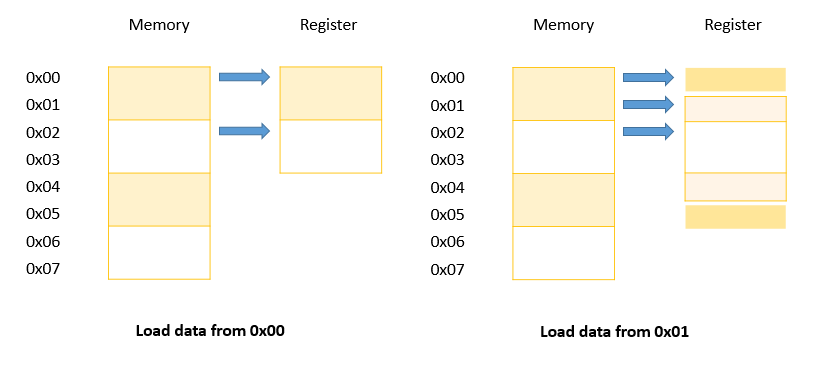
Tuy nhiên khi đến địa chỉ 0x01, do không thuộc vào ranh giới truy cập (địa chỉ ô nhớ chia hết cho 2), nên processor phải làm thêm một số công việc để xử lý là truy cập thêm bộ nhớ, dẫn tới làm chậm lại các hoạt động. Dữ liệu ô nhớ không tương thích như vậy được gọi là "Unaligned memory access".
Quad-byte memory access granularity
Tương tự như Double-byte memory access granularity, nhưng hãy xét cách mà processor xử lý "Unaligned memory access".
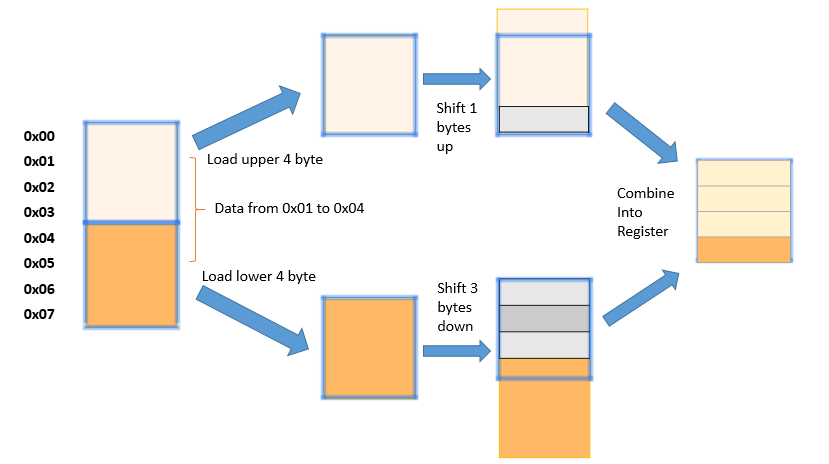
Trường hợp này, muốn lấy được vùng nhớ data, processor sẽ phải lấy 4 byte phái trên và để ô nhớ dịch lên 1 byte và lấy 4 byte phải dưới và dịch lên trên 3 byte, sau đó ghép lại sẽ thu được vùng nhớ data.
Rất nhiều công việc phải thực hiện, như vậy làm giảm rất nhiều hiệu suất của hệ thống.
Vậy nên cần tổ chức thực hiện cơ chế nào đó để không còn Unaligned memory access thì hiệu suất của hệ thống sẽ tăng lên rất nhiều. Đó là lý do tại sao cần Data Alignment.
Thử nghiệm
Để so sánh hiệu suất và thời gian xử lý, cần bài thử nghiệm so sánh giữa các mô hình: Sử dụng kết quả thực nghiệm của Jonathan Rentzsch, bài thử nghiệm được thực hiện trên hệ thống Macbook Pro, quad-core 2.8 GHz Intel Core i7 64-bit processor, 16GB RAM.
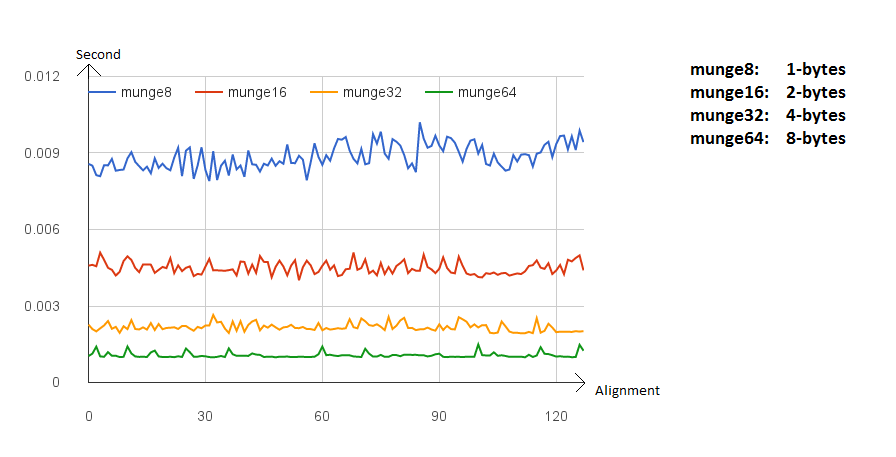
Có thể xem chi tiết thông số trong Table Result
Struct Alignment
Xét kết quả ví dụ của bài viết trước:
struct Student
{
char id;
int age;
double gpa;
};Kết quả thu được là:

Kích thước của struct là 16 chứ không phải 13, và vùng nhớ cấp phát cho struct luôn luôn là liên tục trong bộ nhớ, địa chỉ của id, age, gpa lần lượt là 0x04, 0x08, 0xC.
Tại sao phải "padding", để tạo nên 1 vùng nhớ "thừa"?
Tuy thấy vùng nhớ đó thừa, tuy nhiên nó làm hạn chế rất nhiều process rơi vào trường hợp địa chỉ phần tử nằm ô nhớ không chia hết cho 2.
Liên hệ với trường hợp Quad-byte memory access granularity, nếu như vùng nhớ data tương ứng với biến int mà lại nằm tại ô nhớ 0x05 thì rõ ràng process sẽ phải làm thêm nhưng việc như trên. Đó là lý do tại sao phải có Data Alignment.
Tham khảo
- Struct Alignment trong C++.
- Kết quả thử nghiệm các mô hình của Jonathan Rentzsch.
- Có thể tham khảo mã nguồn sử dụng để thử nghiệm bên dưới.
/**
* File: data_alignment.c
* This is a collection of simple functions that attempt to read
* from a 5MB file in varying sizes and with different buffer
* alignments.
*
* The munge* functions are derived from Jonathan Rentzsch's article
* https://www.ibm.com/developerworks/library/pa-dalign/
*
* This work is inspired by the same article referenced above.
* Before running the examples, create a data file by running:
*
* base64 /dev/urandom | head -c 5000000 > datafile
*
* This will create a 5MB file with random textual data in it.
* However, a file with any size can be used.
*
* The results of a sample run can be viewed at
* https://docs.google.com/spreadsheets/d/17tfu_kl4w5Ad8Sqpdh4nl5GEenH8VF6vZY0lh7MDxhI/edit?usp=sharing
* The test was run on a Macbook Pro with a quad-core 2.8 GHz Intel Core i7 processor and 16GB of RAM.
*/
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <time.h>
#include <math.h>
#define USAGE_ERROR 1
#define INPUT_FILE_ERROR 2
#define MEM_ERROR 3
#define FILE_READ_ERROR 4
#define NUM_MUNGE_FXNS 4
#define NUM_TRIES_PER_RUN 10
#define NUM_INCREMENTS 128
//
// `size` is the amount of data we want to process, in this case 5MB
// `*data` is a pointer to the buffer we want to read.
// We're going to stagger the alignment to the data buffer by incrementing
// the pointer to the buffer and running each test again.
//
static void munge8(void *data, uint32_t size)
{
uint8_t *data8 = (uint8_t *)data;
uint8_t *data8End = data8 + size;
while (data8 != data8End)
{
*data8 = -*data8;
data8++;
}
}
static void munge16(void *data, uint32_t size)
{
uint16_t *data16 = (uint16_t *)data;
uint16_t *data16End = data16 + (size >> 1); /* divide size by 2 */
uint8_t *data8 = (uint8_t *)data16End;
/* strip away upper 31 bits */
uint8_t *data8End = data8 + (size & 0x00000001);
while (data16 != data16End)
{
*data16 = -*data16;
data16++;
}
while (data8 != data8End)
{
*data8 = -*data8;
data8++;
}
}
static void munge32(void *data, uint32_t size)
{
uint32_t *data32 = (uint32_t*)data;
uint32_t *data32End = data32 + (size >> 2); /* Divide size by 4. */
uint8_t *data8 = (uint8_t*)data32End;
uint8_t *data8End = data8 + (size & 0x00000003); /* Strip upper 30 bits. */
while (data32 != data32End)
{
*data32 = -*data32;
data32++;
}
while (data8 != data8End)
{
*data8 = -*data8;
data8++;
}
}
static void munge64(void *data, uint32_t size)
{
double *data64 = (double*)data;
double *data64End = data64 + (size >> 3); /* Divide size by 8. */
uint8_t *data8 = (uint8_t*)data64End;
/* Strip upper 29 bits. */
uint8_t *data8End = data8 + (size & 0x00000007);
while (data64 != data64End)
{
*data64 = -*data64;
data64++;
}
while (data8 != data8End)
{
*data8 = -*data8;
data8++;
}
}
static float run(void(*mungeFxn)(void *, uint32_t), void *data, uint32_t size)
{
clock_t start;
clock_t stop;
float duration;
start = clock();
mungeFxn(data, size);
stop = clock();
duration = (float)(stop - start) / CLOCKS_PER_SEC;
return duration;
}
static float calculateAverage(float *runtimes, int len)
{
float sum = 0;
for (int i = 0; i < len; i++) {
sum += runtimes[i];
}
float average = sum / len;
//fprintf(stderr, "Sum: %f; len: %d, Average: %f ms\n", sum, len, average);
return average;
}
static float performRuns(void(*func)(void *, uint32_t), char *buffer, long bufSize)
{
float runtimes[NUM_TRIES_PER_RUN];
float duration;
for (int i = 0; i < NUM_TRIES_PER_RUN; i++) {
duration = run(func, buffer, (uint32_t)bufSize);
runtimes[i] = duration;
}
duration = calculateAverage(runtimes, NUM_TRIES_PER_RUN);
return duration;
}
static float *incrementPointerAndRun(void(*func)(void *, uint32_t), char *buffer, long bufSize)
{
float *result = (float *)malloc(sizeof(float) * NUM_INCREMENTS);
for (size_t j = 0; j < NUM_INCREMENTS; j++) {
result[j] = performRuns(func, buffer++, bufSize--);
}
return result;
}
static void runAll(char *buffer, long bufSize, float **result)
{
void(*func[])(void *, uint32_t) = { &munge8, &munge16, &munge32, &munge64 };
int len = sizeof(func) / sizeof(func[0]);
for (int i = 0; i < len; i++) {
result[i] = incrementPointerAndRun(func[i], buffer, bufSize);
}
}
static void getFileDataAndSize(FILE *file, char **buffer, long *fileSize)
{
size_t lengthRead;
// obtain file size
fseek(file, 0, SEEK_END);
*fileSize = ftell(file);
rewind(file);
// allocate memory to contain whole file
*buffer = (char *)malloc(sizeof(char) * *fileSize);
if (*buffer == NULL)
{
fprintf(stderr, "Memory error\n");
exit(MEM_ERROR);
}
// copy file into buffer
lengthRead = fread(*buffer, 1, *fileSize, file);
if (lengthRead != *fileSize)
{
fprintf(stderr, "File read error\n");
exit(FILE_READ_ERROR);
}
}
static void printResults(float **result)
{
for (size_t i = 0; i < NUM_MUNGE_FXNS; i++) {
fprintf(stderr, "munge%lu: ", (size_t)pow(2, (3 + i)));
float *row = result[i];
for (size_t j = 0; j < NUM_INCREMENTS; j++) {
fprintf(stderr, "%f | ", row[j]);
}
fprintf(stderr, "\n");
}
}
int main(int argc, char const *argv[])
{
if (argc < 2)
{
fprintf(stderr, "Usage: data_alignment <10MB file>\n");
exit(USAGE_ERROR);
}
const char *filename = argv[1];
FILE *file = fopen(filename, "r");
if (!file)
{
fprintf(stderr, "Unable to open file: '%s'\n", filename);
exit(INPUT_FILE_ERROR);
}
char *buffer;
long fileSize;
getFileDataAndSize(file, &buffer, &fileSize);
#ifdef TESTRUN
for (size_t i = 0; i < fileSize; i++) {
fprintf(stderr, "%c", buffer[i]);
}
fprintf(stderr, "\n");
#endif
float **result = (float **)malloc(sizeof(float *) * NUM_MUNGE_FXNS);
if (result == NULL)
{
fprintf(stderr, "Memory error\n");
exit(MEM_ERROR);
}
runAll(buffer, fileSize, result);
printResults(result);
// clean up
if (buffer)
{
free(buffer);
}
if (result)
{
for (size_t i = 0; i < NUM_MUNGE_FXNS; i++) {
free(result[i]);
}
free(result);
}
fclose(file);
return 0;
}